题目
逻辑回归模型实现对急性炎症的诊断数据进行逻辑回归预测。
参考资料:【ML】一文详尽系列之逻辑回归
代码
1 | import numpy as np |
损失变化函数的曲线图:
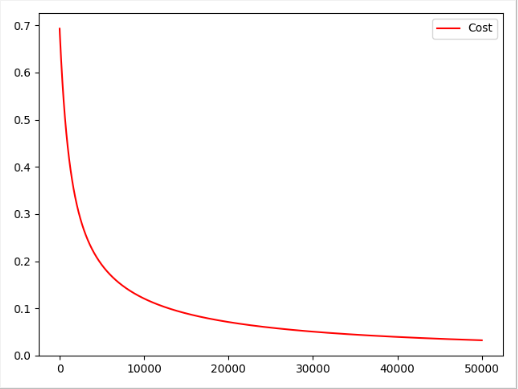
学习率为0.0005,损失函数为均方差损失函数
结语
1、从数学的角度谈谈你对梯度的理解?
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。比如函数f(x,y), 分别对x,y求偏导数,求得的梯度向量就是(∂f/∂x, ∂f/∂y)T,简称grad f(x,y)或者▽f(x,y)。对于在点(x0,y0)的具体梯度向量就是(∂f/∂x0, ∂f/∂y0)T.或者▽f(x0,y0),如果是3个参数的向量梯度,就是(∂f/∂x, ∂f/∂y,∂f/∂z)T,以此类推。
那么这个梯度向量求出来有什么意义呢?他的意义从几何意义上讲,就是函数变化增加最快的地方。具体来说,对于函数f(x,y),在点(x0,y0),沿着梯度向量的方向就是(∂f/∂x0, ∂f/∂y0)T的方向是f(x,y)增加最快的地方。或者说,沿着梯度向量的方向,更加容易找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是 -(∂f/∂x0, ∂f/∂y0)T的方向,梯度减少最快,也就是更加容易找到函数的最小值。
具体看这:https://www.cnblogs.com/pinard/p/5970503.html
2、实验中遇到的问题:
为什么在求梯度的时候不加上sigmoid函数的导数?